 کتابدار 2.0 مجله کتابداری و کتابخانه 2.0
کتابدار 2.0 مجله کتابداری و کتابخانه 2.0

مقدمه
در جلسه قبل یک معرفی اولیه از نرم افزار بیان کردیم. دانلود و نصب نرم افزار، نحوه ورود داده ها به نرم افزار، فرمتهای مورد قبول نرم افزار از پایگاههای مختلف را توضیح دادیم.
یک مرور از فرایندهای آماده سازی داده ها برای نرم افزار داشته باشیم:
- ابتدا داده های کتابشناختی را مطابق نیازمان با طراحی راهبرد جستجوی مناسب از پایگاه های استنادی (یا اطلاعاتی) دانلود و ذخیره می کنیم.
- درنرم افزار قبل از هر چیز به فایلی که می خواهیم ایجاد کنیم یک نام با پسوند txt اختصاص می دهیم(ترجیحا عدد یا نام انگلیسی)
- بعد از انتخاب فایل( یا فایل ها) و به نرم افزار فرمان میدهیم که همه فایل ها را یکی کن( به هم بچسبان). نتیجه ایجاد یک فایل txt است با نامی که خودمان به آن اختصاص دادیم
- در مرحله بعد به نرم افزار فرمان می دهیم یک خط اطلاعاتی اضافه را از پیشینه های کتابشناختی حذف کند. نتیجه ایجاد فایلtx2 است.
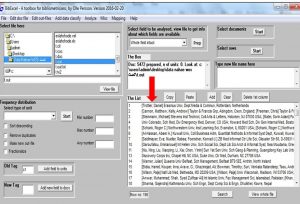
- حالا باید از نرم افزار بخواهیم فایل tx2را به شکل دیالوگ(مثل نقش آفرینان فیلم ها و یا نمایشنامه ها هر کس دیالوگ خودش را دارد!) در بیاورد. نتیجه ایجاد فایل با پسوندdoc است. حالا نرم افزار می تواند روی این فایل کارهای تحلیلی انجام دهد.ما فایل doc را ایجاد کردیم تا با ایجاد یک نظم قابل فهم برای نرم افزار بتوانیم عملیات مختلف و مورد نیازمان را روی داده های کتابشناختی پیاده کنیم. ابتدا فایل doc را باز کنید تا یک دید روشن تر از داده ها پیدا کنید. همانطور که در شکل می بینید محتوای یک پیشینه کتابشناختی به صورت زیر است. هر کدام از نواحی اطلاعاتی یا فیلدها یک نام اختصاصی دارند. سمت چپ تصویر نام فیلدها به شکل حروف تکی یا دو حرفی(بخوانید برچسب یا تگ[۱]) آمده است. برخی از برچسب ها را با فلش زرد نشان داده ام. به عنوان مثال برچسب AU ناحیه اطلاعاتی نویسنده را نشان میدهد. و یا TI عنوان منبع را نشان می دهد. DE کلیدواژه های سند را نشان می دهد(فلش آبی). C1 افیلیشن[۲] یا آدرس نویسنده را نشان می دهد(فلش سبز). به همین ترتیب تمام بخشهای پیشینه کتابشناختی بوسیله یک برچسب مشخص شده است. با دقت در این نواحی اطلاعاتی می توانید محتوای فیلدها را تشخیص دهید. اگر نتوانستید برخی از نواحی را تعریف کنید اینجــا را ببینید. پایان هر کدام از فیلدها با یک خط عمودبسته شده است(فلش قرمز).

فیلد آدرس نویسندگان یا افیلیشن درپیشینه کتابشناختی با برچسب C1 وRPنشان داده می شود. در بعضی از پیشینه ها فقط فیلدRPبرای آدرس نویسنده می آید. دقت کنید که نام نویسنده در داخل براکت قبل از آدرس نویسنده قرار می گیرد. و در مورد آدرس ابتدا نام سازمان اصلی و در پایان نام کشور قرار میگیرد. خب حالا فرض کنید می خواهیم نام نویسنده را از آدرس حذف کنیم.
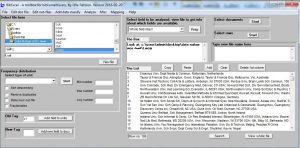
در قسمت select file فایل doc را انتخاب کنید. بعد در بخش Old Tag برچسب C1 را بنویسید. و نهایتا در بخشselect field to be analysed گزینه Whole field intact را انتخاب کنید. نتیجه فایل out است. در قسمت the list براکتهای شامل نام نویسنده را می توانید، ببینید.
حالا از منوی Edit out files گزینه Remove [..] from whole field را کلیک کنید. نتیجه ایجاد فایل wcm است که براکت از آن حذف شده است.
از منوی Edit outfiles گزینه Decompress outfile را انتخاب کنید. اولین پنجره را ok و برای پنجره دوم no را کلیک کنید. فایل nnu نتیجه این فرایند است که در آن هر آدرس در یک ردیف قرار گرفته است.

حالا اگه بخواهید کشورها را بررسی کنید در گام اول باید کاما را به اسلش تبدیل کنید. مسیر زیر را بروید:
Edit outfiles/Convert comma-delimited addresses
نتیجه پردازش نرم افزار فایل odr است که به جای کاما اسلش و دابل اسلش قبل از نام کشور ها را دارد

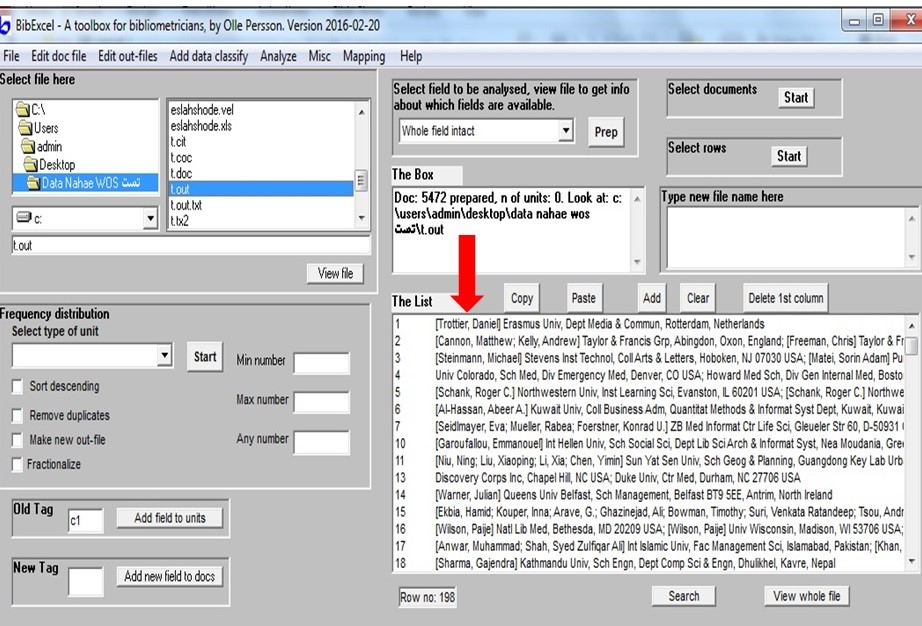
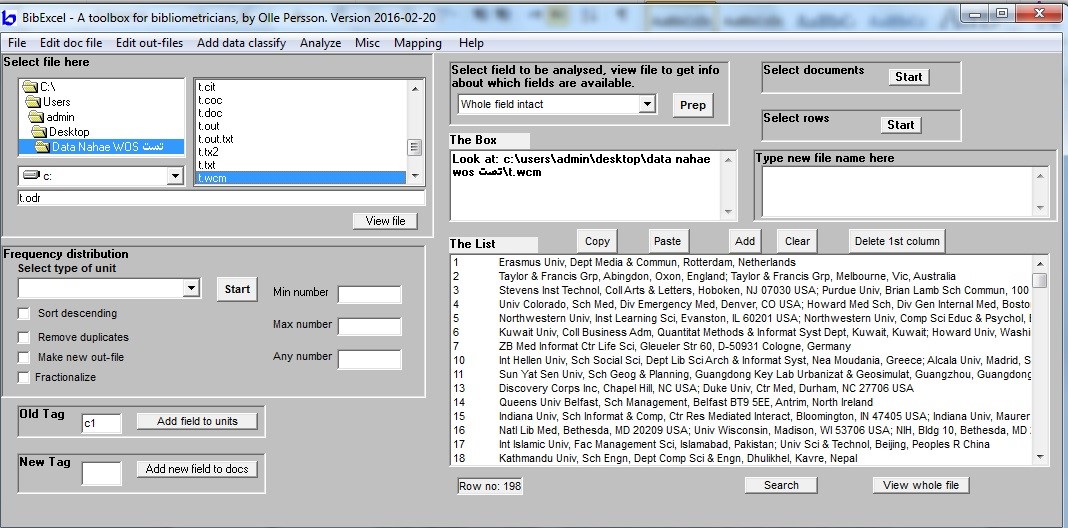


مطابق عکس زیر گزینه ها را انتخاب کنید.

نتیجه پردازش نرم افزار فایل OUX است که نام کشورها را با حذف موارد تکراری نشان می دهد.
اگر به جای برچسب C1 بخواهید از RP استفاده کنید، فرایندها با کمی تغییر مطابق موارد بالاست.بعد از انتخاب فایل docاز مسیر زیر بروید:
Edit outfiles/Standardize addresses/Clean and add address fields
بعد چند پنجره باز می شود گزینه yes و ok را بزنید. فایل OUXتشکیل می شود بقیه فرایند مانند مراحل بالا است که در مورد برچسبC1 توضیح داده شد.
حالا فرض کنید ما نام نویسنده ها و آدرسشان را میخواهیم. پس یک فایل می خواهیم با دو ستون یکی نام نویسندگان و ستون دوم افیلیشن.
در گام اول یک فایل out با برچسب c1 ایجاد کنید.

حالا از منوی Edit out file گزینه Extract author name and address from C1 field را انتخاب کنید.
فایل oxx درهر ردیف یک نویسنده و یک آدرس دارد. البته برخی از ردیف ها ممکن است، ناقص باشند که لازم هست با اکسل فایل را باز کنید. موارد لازم را اصلاح کنید و با همان نام قبلی ذخیره کنید.
می توانید نام نویسنده را استاندارد کنید. مطابق عکس ما ستون اول (شماره سندها)و سوم(نام نویسنده) را می خواهیم.
در قسمت The box مطابق عکس بنویسید: ۱/۳
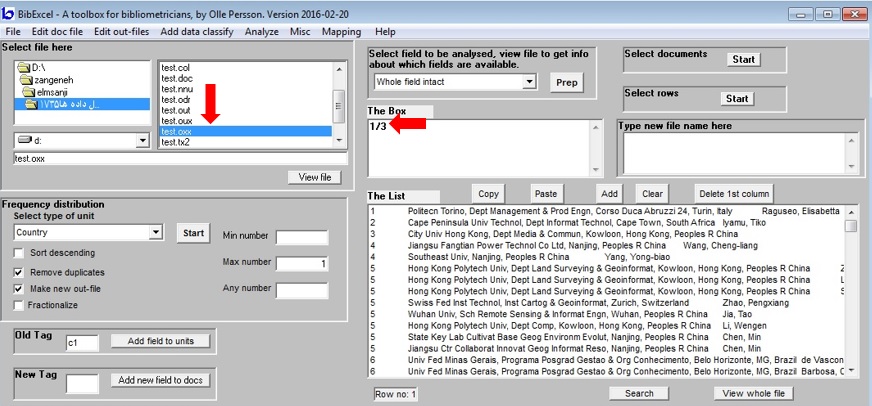
بعد از منوی Edit out file گزینه select columns را انتخاب کنید. نتیجه ایجاد فایل col است. اگر دقت کنید فقط ستون اول و سوم در این فایل آمده است.

حالا مانند عکس مسیر زیر را بروید:

سه پنجره باز می شود اولی را ok کنید و برای دوپنجره دیگر yes را بزنید. فایلی با پسوند Loa تشکیل می شود که لیست نام استاندارد نویسندگان را دارد.

حالا شما می توانید در فایل oxx- که با اکسل باز کردید- در ستون D نام استاندارد نویسندگان را وارد کنید و از آن استفاده کنید.

[۱] .Tag
[۲]. affiliation
| مشخصات استناددهی به این مقاله | |
| نویسنده(ها): | ثریا زنگنه |
| عنوان مقاله: | نرم افزارهای علم سنجی( نرم افزار Bibexcel قسمت۲) |
| عنوان مجله: | کتابدار ۲.۰ – (عنوان لاتین: Kitābdār-i 2.0) |
| دوره مجله(Vol): | ۸ |
| شماره مجله(Issue): | |
| سال(Year): | ۱۴۰۱ |
| شناسه دیجیتال(DOI): | |
| لینک کوتاه: | http://lib2mag.ir/12802 |




سلام.
داشتم اپلیکیشن بهخوان(شبیه گودریدز) ولی ایرانی است را می دیدم.اسمبچه های مقاله نویس و نویسنده شما همبه صورت پیش فرض به عنوان نویسنده وجود داشت و اگه دوست داشتند ویرایش وکاملش کنند .
بهخوان آینده خوبی در پیش دارد…